In my current role, in addition to my manager, I have three clear dotted line reporting relationships. If you’re not familiar with the term, picture an organizational chart. Reporting relationships are depicted with lines, connecting employees to their manager. A dotted line relationship is an informal reporting relationship. Using my current role as an example, I report to the CFO and have dotted lines to the CEO, company owner and a VP. All of these folks play some part in reviewing and/or approving work my department does.
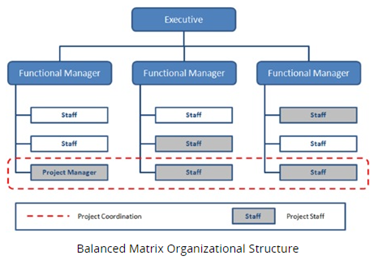
This is a little different from a matrix org structure in which there are two or more formal reporting relationships. For instance, a software developer reporting to both a project manager leading the software project they’re on as well as a functional manager.
Dotted line relationships are very common, especially in middle management roles. I’ve personally had these reporting relationships throughout my career. They are not without their challenges. This post is my attempt to articulate some of my learnings.
One potential challenge is conflicting expectations. You have to be careful with this one. Your first impulse might be to simply side with the person highest on the org chart. Always remember you have a duty to your formal manager. Keep them in the loop always. When there’s a conflict, go to them with it. As long as you are maintaining a good relationship with your manager, they will help. And they may just give you their blessing to do what the CEO, or whoever that higher status person is, says. They will appreciate you coming to them.
Also, and this is very important, be careful not to throw one dotted line under the bus when talking with another. It is easy to do this unintentionally – “ok, but Melissa said X”. As a human, you have a pre-frontal cortex providing you executive function. Use it!
Another challenge is inefficient or siloed communication. This one has a tie-in with conflicting expectations in that, if you’re typically meeting with each of your DLs one-on-one, you will likely end up in the middle of conflicts. Whereas if they’re all in the same room, they will naturally work out the conflicts with each other then and there. Try not to have separate status meetings with each of them. Do your best to corral them. Do not be afraid to point out the benefits of collaboration and alignment facilitated by meeting as a group.
In reality it may be difficult to achieve this. Some leaders prefer to have you one-on-one. It can also simply be a logistical hurdle to harmonize schedules of busy people. One tip I will give is, again, respect your formal reporting relationship. Include your manager on communications and invite them to meetings of strategic or financial significance, even if they may not be the primary audience. They must at least be given the option to stay informed.
Another communication tip – if you cannot get the whole band together for status meetings, mind the timing and order in which you meet with your DLs. For instance, you may want to schedule the regular status meeting with your formal manager earlier the same day you meet with the CEO. That way, they will both be working with the same current information. I learned this the hard way. After meeting with the owner of the company, I’ve had him go to the CEO and ask him about something we discussed. The CEO was not up to date on the topic and was caught off guard. Needless to say I learned my lesson. Keep all your DLs up to date. But make sure you do it in a way that no one will be blindsided by another.
And how do you know which DLs to go to for approval or consultation on any one specific matter? It is not always clear. And your formal manager may not always even know. This is something you’ll have to learn over time. It is part of the organizational tribal knowledge. While you are learning, err on the side of involving more DLs.
If this all sounds tricky, it can be. But in the scheme of things, it really doesn’t require a PhD. It’s a learnable skill. Just be thankful you have so many people taking interest in your work 🙂
Here’s a short anecdote illustrating the other side of the coin. I once worked for a SaaS company that was acquired. My manager’s role was eliminated. When my new boss from the acquiring company wouldn’t answer or return my calls, it wasn’t a good feeling (or a good omen). You WANT to be valued!
I’d love to hear about others’ experience with dotted line relationships. There are lots of situations I didn’t get into, like dotted lines to people outside the organization, reporting to a board of directors, etc. What are some of your tips for connecting your dotted lines?